
--Author:ViewDAO.DaPangDun、ViewDAO.zhihong、ViewDAO.realAlitta
1、Introduction
👆Following the previous article, we analyzed the liquidity problem of NFT. In the article, we pointed out:
If NFT is to be combined with DEFI, most important infrastructure is the "NFT oracle"
In this article, we will discuss with you the NFT oracle-related projects on the market and the pricing mechanisms or models they use to fully understand the current development direction and development of this track.
2、Project research
We have collected the current oracle projects for NFT prices, mainly including:
Abacus 、Upshot、Nftgo、Banksea、Chainlink
Among them, Nftgo has not found any related oracle mechanism for the time being. The official website said that it will be developed. It is estimated that it has not been done well, so it is excluded.
Chainlink is also trying to intervene in the field of NFT oracles, but there is no corresponding data to analyze. It uses TWAP to give the floor price of NFT. I will not do a detailed analysis here.
Let's understand one by one 👇👇
1、Abacus
Website、white paper、related materials
1.1 Introduction
Abacus has two pricing mechanisms:
1.1.1 Peer incentive pricing (explained in detail in the previous article, refer to 3.5)

1.1.2 Abacus Spot (explained in detail in the previous article, refer to 3.5)
Abacus Spot realizes real-time valuation of NFT by creating a liquid market for traders to speculate on the value of NFT pools.
Liquidity is generated by traders initially entering the pool and further minting throughout its lifetime. The protocol ties the value of NFT transactions to the true NFT value by requiring owners to exit either by paying a fee to the holder or by exchanging the proceeds for liquidity in the pool through a public auction.
1.2 How does it work?
1.2.1 Create a pool
- NFT owners first deposit their NFTs into the pool repository, opt-out of fees, representing the initial NFT valuation of their NFT pool’s tokens. The NFT is now locked in the pool and the only way to withdraw it is to pay an exit fee or sell it in an auction.
- Start a Dutch auction for pool tokens (at initial NFT valuation) and end when the initial supply of tokens is sold out. The starting valuation is based on the total amount of ETH provided to the vault during the auction. For example, if a total of 100 tokens were sold for 0.1 ETH, the valuation of the NFT starts at 10 ETH.
When a mining pool is active, pool owners have “credentials” which give them the right to withdraw NFTs from the pool by paying an exit fee to token holders or selling them in an auction. Using credentials, NFT owners can trade, lend, or borrow using the value reflected in the pool. Additionally, pool owners receive transaction fees generated by the pool's trading volume, similar to typical DEX liquidity providers.
1.2.2 Trading
1)After creating the pool, you can start trading. The pool operates as an Automated Market Maker (AMM).
This is the origin of the real-time price of NFT: the value of the pool is the real-time price of NFT
2)If the NFT is considered to be undervalued, there may be a rush to buy the tokens in the pool, and if the supply of tokens in the pool cannot cover the valuation of the NFT, the buyer will short the pool. As a result, interested speculators can mint new coins at a premium in the event that the pool’s token supply dries up.
1.2.3 Vault closed
Vault closing occurs in one of two ways:
1)Close the auction
The first way to withdraw locked NFTs is to auction NFTs (where the owner can participate). In order to initiate an auction, owners start voting, which must be approved by token holder votes. At the start of the auction, transactions are locked and no other users are allowed to enter or exit the liquidity pool. After the auction,
--The auction price of NFT will be given to all holders of NFT tokens, which will be distributed according to the proportion of ownership (it may be a loss or a profit)
--The winning bidder will get NFT
--NFT owners get the value of the pool
2)Give an exit fee to exit
The NFT owner pays an exit fee to redeem the NFT, and the exit fee will be distributed by all token holders in proportion to their ownership. As mining pools will compete with each other for liquidity, we expect the exit fee percentage to reach market equilibrium as owners must choose an exit fee high enough to incentivize participation.
For related examples, you can refer to some of the content in the previous article (refer to 3.7.3)

1.3 What is the point of Abacus Spot?
1.3.1 Lending
Because the price of NFT is the real-time value of the pool (because it is a competition, it can reflect the actual value of NFT), so it can seamlessly participate in lending.
1.3.2 Lever
Interestingly, this pricing method allows NFT owners to use leverage (NFT owners buy in the liquidity pool themselves, which is equivalent to using leverage).
In fact, in addition to buying tokens, traders have the opportunity to short NFT pools they believe are overvalued, according to officials.
2. Upshot
2.1 Introduction
Upshot One is committed to becoming a common NFT oracle project on the market, and its pricing mechanism has gone through two stages:
- Q&A protocol
- Machine Learning
2.2 Q&A protocol
By devising a series of mechanisms to let the agents (the people answering the question) answer the question honestly and with high quality, and then select the highest quality answer as the "answer" to the question.
2.2.1 Progress
- Ask a question: ask a question and list options
- Answer: The agent answers the question after placing the bet
- Selection: Agents randomly choose to answer questions based on their share of wagers
- Scoring: The selected agent's answer is scored and used as the solution to the problem
- Fork: A series of questions and answers can be forked if the attack is successful or reflects different preferences
Step 1: Ask questions
Anyone can ask questions on Upshot, but must follow these rules
- List possible answers to their questions (eg "yes or no" or "greater than less")
- State how much confidence the agent should have in their answer (confidence is measured by the total amount of stake the agent has put in)
- Define filtering criteria that limit who's answers can be considered (e.g. "people who hold X governance tokens" or "agents on this beta tester whitelist")
- Pay the fees awarded to successful agents, in any currency
Step 2: Answer
The agent puts in a bet and then answers as many questions as possible as honestly as possible. The higher the stake, the higher the confidence, the more questions can be answered, and the more likely it will be accepted as the final answer.
Step 3: Choose
Upshot will "randomly sample without replacement" 3 proxies as subsequent scored answers.
- Adoption of no-replacement sampling ensures that "creating many fake accounts, each holding a small amount of bet is never more profitable than direct betting on a large bet account".
- Random sampling requires a random seed to ensure sampling is truly random and unpredictable. Upshot One ensures random seeds through a two-step process. First, the seed is chosen in advance, and will be chosen in future blocks, which is hard to predict before its creation. Second, after the chosen blockchain is actually computed, it is used as input to Chainlink's Verifiable Random Function (VRF) service, which outputs a cryptographically secure nonce, and this output nonce is used as Upshot One The random seed chosen by the agent.
Step 4: Scoring
Feed the selected proxy answers to Upshot One's peer-to-peer prediction mechanism in an attempt to elicit honest information without any means of verification (i.e. not necessarily ground truth). And this peer-to-peer prediction mechanism has the characteristics of non-minimum mechanism, multi-tasking and DMI mechanism.
Explain a few terms:
[Non-minimal mechanism]: It is to ask participants to provide information beyond the answer itself. That is, they asked participants how likely it was that others would say the same answer as them, and the participants who scored the highest were either "least surprised" or "least wrong" or "most predictive."
[Multitasking]: Let the agents answer as many questions as possible to increase the relevance of the answers
[DMI mechanism]: This means that at least three participants must answer at least 2C questions (where C = the number of possible answers, so C = 2 for "yes or no" questions) in order to score any set of answers. Participants' answers were aggregated into columns and indexed by their respective questions.
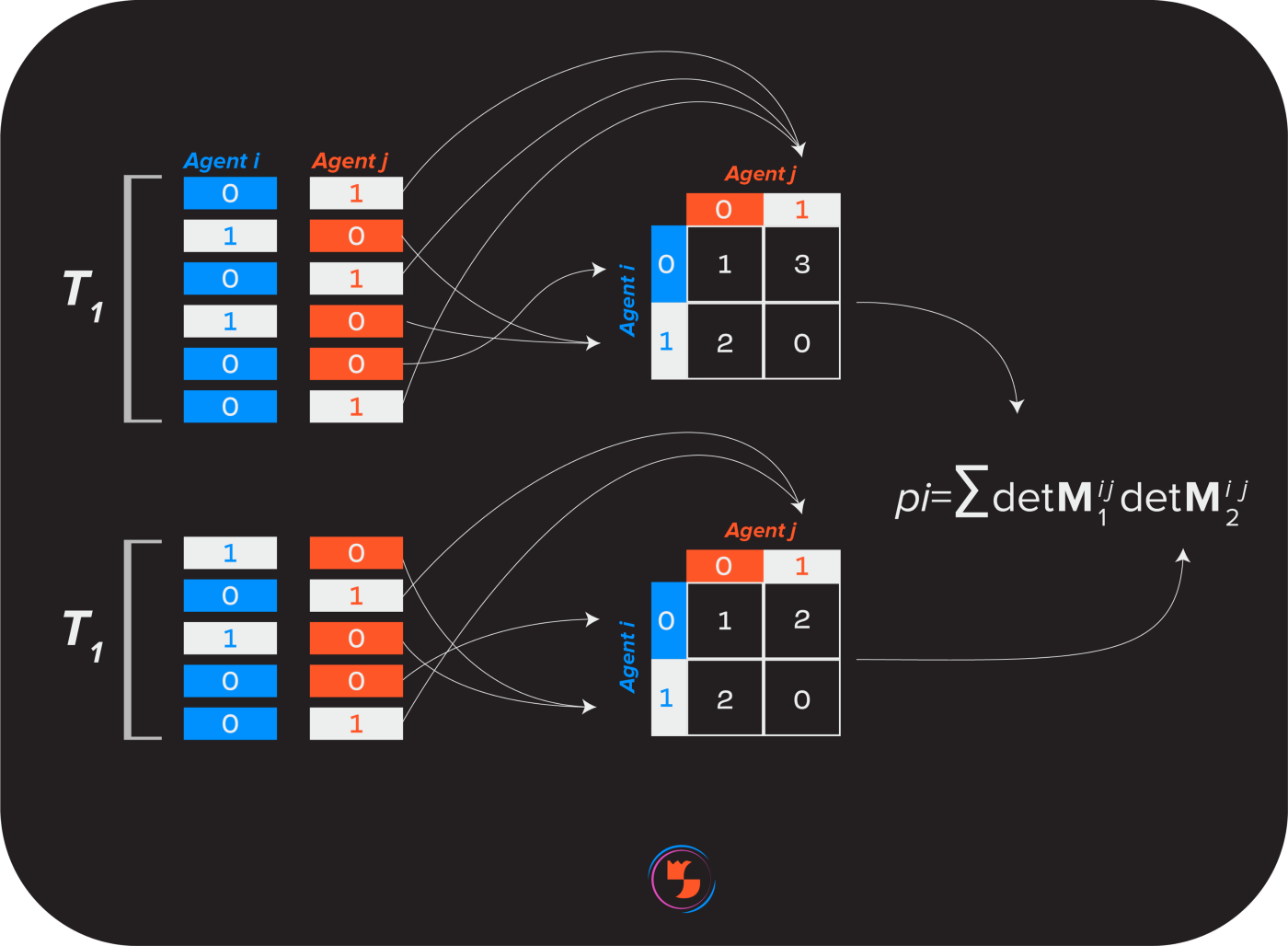
The columns are paired with each other and then split in half. Each "half-column pairing" was transformed into a matrix listing the number of overlapping answers between participants. For a binary question of "yes or no", a 2x2 matrix is formed, then the determinant of the matrix is calculated and multiplied by another matrix.
If an agent always says "yes" despite the fact that honest answers to certain questions are a mix of "yes" and "no", then whenever a contradictory agent is paired with an honest agent, their The score will be lower.
Step 5: Fork
The nature of a problem may be subjective, and one may wish to resolve again (for example, if you said "yes" and you liked the outfit, but the problem was resolved as "no", then perhaps you should use a different set of resolutions) scheme to curate your fashion), so Upshot allows forking (i.e. breaking away) a series of resolutions.
2.2.2 Result
Upshot originally planned to use this question-and-answer protocol to price NFTs on the market, such as asking whether the price of the NFT is between 1~2ETH, or whether the price of X NFT is higher than that of Y NFT, etc. to determine the price of NFT, but this This method has obvious disadvantages:
- It is not easy to expand. If the scale of the NFT market is too large, the problem volume is too large if it is to be accurately priced, which is not suitable for this fast-changing large-scale NFT market;
- The result evaluation is not very accurate.
Therefore, the project party gave up using this question-and-answer mechanism to price NFTs, and turned to machine learning (ML) with high scalability, high accuracy, and high efficiency to give NFTs a fully automatic and smoother pricing.
2.3 Machine learning model
Upshot's machine learning model is based on historical sales data and NFT metadata to comprehensively analyze and predict, and based on these valuable information and historical sales data, it is converted into a denser and richer data set, rather than relying only on a single NFT. Price trends to generate accurate and reliable pricing.
2.3.1 Introduction
- A machine learning model extracts historical sales data, bid/ask, and NFT metadata to build features based on this information, resulting in accurate, reliable pricing.
- Validate the predictions by checking their accuracy on data not used during training, and get a margin of error by comparing the model's predictions to the actual sales price.
- Both the predicted price and the margin of error provide useful information for NFT buyers, sellers or developers to build products on top of the NFT economy.
Machine learning models are able to incorporate data not considered by simpler models, such as aggregating NFT sales histories to predict a single NFT and leveraging a range of NFT metadata. Much of the current project's research efforts are focused on building different predictors, using automated methods to discover the most important variables, and iterating to obtain a lean but robust model.
2.3.2 Features
Shapley
The model uses Shapley values to reveal the importance of different variables used in the model.
This helps explain how a complex ML model reaches its predicted NFT price, which is useful for further model development and understanding unexpected predictions.
Such analysis also helps to visualize the underlying drivers of NFT prices and identify the variables that really matter to each NFT project.
rarity value
The model constructs a rarity value based on the combination of attributes of the NFT, and the basic idea behind it involves calculating the probability of observing the attributes of the NFT. The higher this probability, the lower the rarity score. The lower the probability, the rarer, resulting in a higher rarity score.
Current models achieve fast approximations to these probabilities because it is computationally complex to compute them precisely given a large number of possible combinations. In addition to calculating the first-order rarity score, the model also calculates a second-order score, which takes into account not only the probability of observing a specific attribute, but also the probability of different pairwise combinations of attributes within the group.
This method of calculating rarity can be extended to arbitrarily high-order rarity and other NFT projects beyond CryptoPunks, where a fixed set of NFTs are issued with a fixed rarity value. Projects that release new NFTs over time may have new features that have never been seen before, requiring more complex calculations of rarity values.
3、Banksea
3.1 Introduction
Banksea aims to build an innovative, secure and efficient NFT pool-based lending center.
The protocol has two main functions: an NFT price oracle and a Pool-based NFT lending platform. The former is the basis of the latter. In this article, we will only introduce the NFT price oracle.
3.2 NFT price oracle
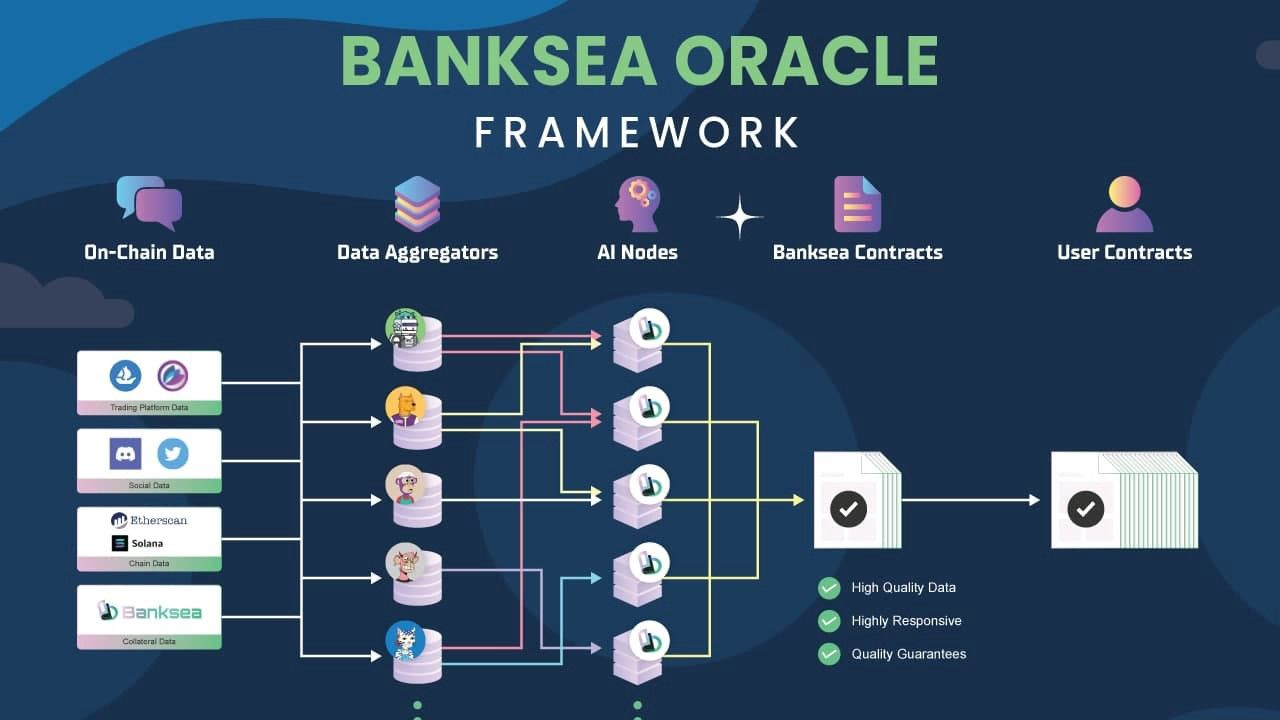
Banksea Oracle Architecture
Banksea Oracle consists of three parts: AI node cluster, on-chain contract, and contract interface.
[AI node cluster]: Crawling NFT-related data, extracting NFT features, and computing AI models.
[On-chain contract]: Aggregated prices provided by distributed AI nodes to provide the final NFT price and risk assessment.
[Contract interface]: Connect to NFT ecology and projects, support the development of customized pricing mechanism, and support user single NFT price query.
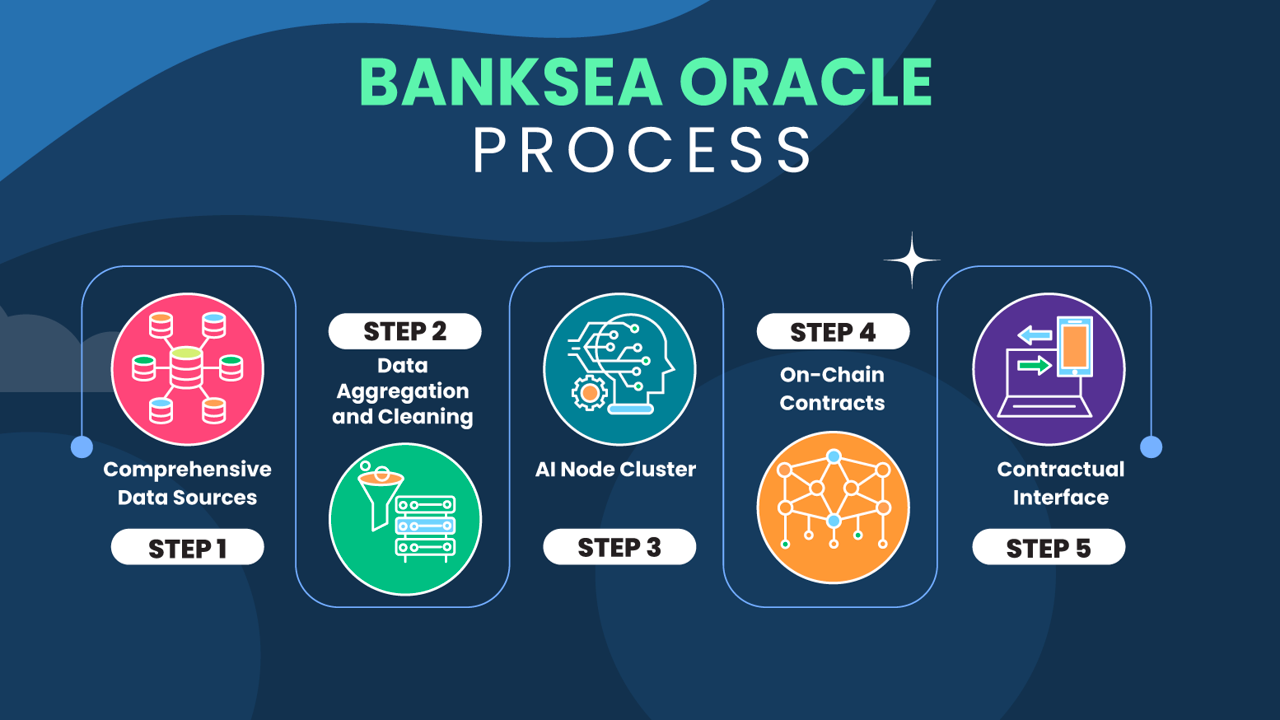
3.2.1 Quote Generation Process
- Get multi-dimensional data:Monitor and capture real-time exchange market data, social media data, NFT data on Ethereum and solana chains, and provide data support for NFT valuation.
- Data aggregation cleaning:Aggregate and clean NFT data of different dimensions to generate the required features of the NFT model.
- AI node cluster:Train the model based on the constructed NFT feature historical data, deploy the model, provide NFT quotes and assess the risk.
- On-chain contract:The data is sent to the data demander through the aggregated data on the chain. The oracles of all nodes send data to the smart contract on the chain. After the smart contract removes outliers through a certain logic, it takes out reasonable data and provides it to the data demander.
- Contract interface:AI nodes will periodically provide data to the oracle program, and the oracle program will aggregate and save the data. Saved data can be read by third-party programs. Provides Rust and JS interface request contracts.
3.2.2 How to prevent oracles from being attacked
- NFT project whitelist system: The project party will dynamically adjust the series of NFTs that can be used for quotation according to certain rules
- Dual AI models for quotation and risk assessment, and the input data dimensions are diversified: In addition to the quotation model, the AI node also has a risk assessment model to assess the risk of NFT
3.2.3 How to deal with the large price fluctuations of NFT?
- Real-time valuation to achieve minute-level or even second-level monitoring
- Filter quality NFT assets by whitelisting
3、Comparative analysis
Through the investigation of the above-mentioned projects, our group has conducted many discussions and formed some opinions to share with you.
Abacus Spot
Advantage:
- The price reflects the actual value of NFT: after the game of market participants, although there may be deviations, it tends to approach the value;
- Automatic and real-time price: The price will be reflected in real time in the AMM market, and it can also be obtained by providing API.
Shortcoming
- Large-scale application is difficult: because each NFT needs to take a load shot, it is inconvenient to automate and the efficiency is not high;
- Scaling is more difficult: when the pool is closed, the price disappears, and price-based derivatives are completely impossible to do.
Status
- At present, I observe that its Discord activity is very low, of course, there is also the possibility that people are not busy managing things;
- After Chizi proposed to introduce AMM, in fact, it doesn’t need to be concerned, and it does not consume other things, but how to attract attractive or special liquidity providers to do this AMM is a point that needs to be considered very much;
- The project is still in the development stage.
Evaluation
Therefore, we evaluate that even if Abacus Spot is successful, it will only target some high-net-worth NFTs, and then release the value of these NFTs and intervene in DEFI such as lending. It is unlikely to be the infrastructure for large-scale NFT pricing.
Upshot
Advantage
- Using machine learning algorithms to predict the price of NFTs has the prospect of large-scale pricing;
- According to the introduction on the official website, when the price is given, the error interval of the price will be given, which is a good price reminder for all NFT participants;
- Although the specific algorithm mechanism of Macing Learning is not given, some details (such as variable importance distribution, rarity, etc.) are given, and some prediction cases are given, which is generally pragmatic;
- According to technical experts, Upshot's team is very powerful, and it also has experience in developing pricing mechanisms (Q&A protocol).
Shortcoming
- The flaws of this model of machine learning itself:
- A large amount of data is required for training. At present, whether the effective NFT historical metadata is enough, and whether a suitable model can be trained;
- Generally speaking, machine learning algorithms are prone to overfitting problems, how to solve them, and whether continuous iteration is required;
- For different projects, the attributes that machine learning needs to focus on are different, that is to say, different NFT series will need to train different models, which is actually unfavorable for expanding the market; at the same time, when the attributes of NFTs increase or decrease At the same time, the model will also fail to a certain extent and need to be updated iteratively, which is also a thorny problem to be solved.
Status
- Although there are not many people on Discord, there is still a certain degree of activity. The project party has also received a new round of financing($22 million). I believe that they are more motivated to do things;
- At present, the project party has opened the API test application, as well as the beta version test, you can participate;
- The project party has not released any plans and materials for issuing tokens for the time being, and the main energy is spent on building a real-time NFT evaluation system.
Evaluation
- Our evaluation of Upshot is very high. This machine learning model based on NFT historical metadata makes it possible for NFT to obtain real-time prices, so that NFT and DEFI can reach a historical intersection;
- It may become an infrastructure for future NFT*DEFI;
- Of course, we also need to pay attention: but because it is not a simple algorithm mechanism (such as a weighting mechanism), the price will have a high uncertainty, and the credibility of the price depends entirely on the results and error intervals given by the model, and it remains to be seen in the future performance.
Banksea
Advantage
- The AI model is used to train the NFT data set, thereby generating accurate and efficient forecast prices. Compared with Upshot, more related data is introduced into the data set: such as social data, media data, etc., which enriches the data to a certain extent. dimension;
- The dynamic NFT whitelist filtering mechanism selects high-quality projects, and combines the quotation mode of multi-dimensional data source + AI model + multi-node reward and punishment mechanism to make the quotation more reasonable;
- The project party has also developed a lending mechanism: in terms of lending, it gives lenders risk exposure so that users who are willing to take risks can obtain higher interest, and users who are unwilling to take risks can obtain stable income; Give the mortgagor sufficient time to avoid being liquidated;
- From the perspective of the economic model, the protocol prepares a safe fund pool for bad debts by combining premiums from the insurance fund pool + protocol income distribution, and uses the protocol support module to prevent the risk of depletion of the fund pool, so that the protocol can withstand black swans and become more vulnerable. operate in a robust manner。
Shortcoming
- As a type of machine learning, AI also has possible problems in the above-mentioned Upshot project: whether the data set can train a reasonable model, overfitting, different NFT systems require different models, and NFT feature changes require iterative model problems;
- The official mechanism of the AI model has not been given, and the source code of this part will not be open source according to the reply of the management personnel, so the effect needs to be marked with a question mark;
- The data and documents of the relevant lending mechanism have not been updated at present, only the data of the liquidation part;
- According to the official introduction, it will provide a price response in minutes or even seconds. Whether this can be achieved or not, and whether it needs to consume a lot of computing power to calculate, also needs to be continuously tracked and observed.
Status
- As the winning project of the Solana hackathon, the attention is very high, and the number of Discord is large;
- IDO will be launched in April 2022. High popularity is a good thing and a bad thing. It is possible that the valuation of the primary market will be directly filled. We have made a calculation: the valuation of the primary market is about 100 million US dollars;
- The latest Gitcoin13 donation includes Banksea. If there is a donation, you can go to Discord to apply for OG status. According to the administrator's introduction, there will be an airdrop;
- It released CitizenOne's NFT in January, and holders of NFT can enjoy some rights. Interested friends can study it. Currently, it can be traded in the secondary market.
Evaluation
- We are highly positive of Banksea. Its design concept has been strictly tested by the hackathon, and its AI model and loan mechanism are logically very reasonable.
- It introduces more dimensional data in pricing to ensure the accuracy of pricing, and introduces risk AI mechanism in lending to ensure the safety of borrowing funds and the risk of liquidation.
- It is likely to become an oracle infrastructure for NFT*DEFI, and has a complete project to connect to DEFI.
- Of course, we also need to pay attention: we need to observe the landing effect and actual performance of the project.
Compared
We compared Abacus, Upshot, and Banksea through several dimensions:

4、Summary
1、General thinking
In the last article on "NFT liquidity", we pointed out:
NFT oracle is the most important infrastructure for NFT to improve liquidity, and it is also the basis for the combination of NFT and DEFI.
We very much agree with the words of the Upshot project team:
Trusted NFT Valuations Key to Mass Adoption
because:
- Through the real-time pricing of NFT, NFT can truly be combined with DEFI;
- Information transparency on NFT prices will lead to increased market activity: tools that make it easier for participants to evaluate NFTs can significantly reduce onboarding costs for new users, generate greater revenue for sellers, and increase overall market activity;
- Real-time quotations for NFTs will increase market transparency, reduce information friction in the NFT market, and encourage the participation of the wider developer community—opening the floodgates for a new wave of NFT products and protocols.
2、The current development of NFT oracles
-
If combined with our previous article, we can see that the prediction mechanism of NFT prices has undergone many attempts and developments:
Peer Incentive Evaluation Pricing / Game Pricing / Liquidity Pool Pricing / Algorithmic Pricing /…
-
The current market trend is more inclined to use algorithmic models to price NFT prices in real time. This transformation occurs in response to real needs. If NFTs are to be priced at a large scale, efficiency issues, participation costs, and complexity issues must be taken into account. It is the most ideal result if they can be automatically calculated and run by machines.
-
We analyze that the following two types of algorithm models will have a higher probability of success:
Machine learning models based on multi-dimensional metadata:
-- Focus on predicting the future value of NFTs (give error margins)
--Advantages: [Technical progress in machine learning is very rapid] [Self-adjustment of parameters] [Negative feedback correction based on results] [Does not require too much human intervention] [More narrative] [Higher technical moat]
--Problems to be solved: [How to ensure the accuracy of the calculation model, it takes time to test] [The model needs to be iterated when the NFT attributes change] [Different NFT series need to correspond to different models]
Weight calculation model based on historical metadata:
-- Focus on analyzing the current value of NFTs (confidence intervals are given)
--I haven't seen much of such a project on the market at present (of course, some of the methodologies are definitely there)
--Advantages: [Results are more predictable] [Only parameters need to be adjusted for different NFT series] [Changes in NFT properties may not affect the model itself]
--Problems to be solved: [The adjustment of parameters may require a lot of intervention, which is unfavorable] [The technical pool is shallow and easily copied]
3、Our favorite NFT oracle
3.1 What is a good oracle
We believe that a good NFT oracle should be able to automate the comprehensive pricing of head projects, rather than single and only pricing the floor price. Automation and comprehensive representation of efficiency; the effectiveness of providing quotations should be strong enough, because the market is changing rapidly; the mechanism should be simple enough, the simplest way to solve problems according to Occam's razor principle is the best, and complexity will bring uncontrollable and uncontrollable foreseen risk. Simply put, the input data is comprehensive and clean, the quotation is real-time, and the model is simple.
3.2 what to do
As to Project
According to coinmarketcap statistics, there are a total of 2,100 NFT projects, and the top 10 projects (accounting for 0.5% of the number of projects) account for 70% of the total market value. A good project is simply a whitelist mechanism. At the same time, the whitelist must have a dynamic update mechanism to filter out poorly developed NFT projects and join NFT projects that meet the requirements. (It can be understood that there must be a listing and delisting mechanism)
As to data
The oracle is a price generator. The input source data is processed by the oracle and the price is output. Therefore, making a reasonable oracle first depends on what data needs to be input.

From the data source:
--The small amount of NFT attribute data is the main factor for price determination, and it should be used as the data input by the oracle;
--The data on the NFT chain and the data of the NFT exchange, although there is some noise, are also the data that can most directly reflect the price of the NFT, which also needs to be used as the input of the oracle machine;
--The community data and social media data of the project are too noisy, the processing process is cumbersome, and the model used in the quantification process is complex and not suitable for the data source input by the oracle machine. If it is used, certain means are required to limit the weight.
Oracle model
After having the input data, the oracle machine can choose to use three forms of [rule], [model] or [rule + model] to process the data to generate the final output price.
Since the price of homogenized tokens is relatively continuous, it adopts the form of multi-node data processing and output using rules. Compared with homogenized tokens, the price of NFT is discrete and each NFT has different attributes. Simple rules are not enough. Given a reasonable price, models need to be chosen to price this subject with a more complex pattern.
Considering the real-time requirements of quotation and the interpretability of the model, a simple machine learning model is a better choice. The deep learning model is too complicated, and there will be unpredictable systemic risks in dealing with a complex quotation system.
In addition, the use of models will involve the use of historical data. Whether the price distribution of NFT changes over time is a key factor in determining the length of historical data. This part needs to be determined by fitting the model to the price trend of the head project.
4、Suggestion
We recommend everyone to keep an eye on Upshot and Banksea, and get involved if you have the chance!